
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 내일배움카드
- 머신러닝
- 자바페스티벌
- 서블릿
- 메시지시스템
- 덴디컨설팅
- java
- 전주스터디카페
- 자바스크립트
- 문제풀이
- ux
- 코린이
- iOS개발강의
- 전주독서실
- 딥러닝
- 코딩
- 썸머스쿨예약
- 패스트캠퍼스
- 자바
- ui
- Python
- 파이썬
- 리스트
- jsp
- 빅데이터
- K디지털크레딧
- 바이트디그리
- 스마트인재개발원
- 광주직업학교
- 스프링
- Today
- Total
멀리 보는 연습
머신러닝_서울시 구별 CCTV 현황 분석 본문

1차 프로젝트가 끝난 후 본격적으로 머신러닝을 배우고 있다. 실습 위주로 진행 중인데, 실습 내용을 복습할 겸 정리하면 좋을 것 같아서 하나하나 정리하면서 올려볼 예정이다. 오늘 복습해볼 내용은 서울시 구별 CCTV 현황 분석인데, 복습을 하다보니, 복습이 아니라 새롭게 공부하는 느낌이 들 정도로 유익하다는 생각이 들었다. 그만큼 수업 시간에 놓치는 게 많다는 점ㅠㅠ 하루에 8시간씩 계속 집중하면서 수업듣는 일이 얼마나 어려운지 실감하고 있다. 수료할 때까지 열심히 배워봐야 겠다.
서울시 구별 CCTV 현황 분석하기
- pandas, matplotlib 사용하기
- 서울시 각 구별 CCTV 현황 살펴보기
- 인구대비 CCTV 비율이 높거나 낮은 지역 알아보기
- 각 구별 CCTV 예측치 확인하고 그로부터 CCTV가 과하거나 부족한 지역 시각화
import numpy as np # 라이브러리 3개 불러오기
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='Malgun Gothic') # 한글 인코딩
1. csv 파일 읽기 - 서울시 구별 CCTV 현황
# '경로/파일명.확장자'
CCTV_Seoul = pd.read_csv('data/CCTV_in_Seoul.csv')
CCTV_Seoul.head() # .head() : 기본 성절된 (디폴트) 5개 값 가져오는 함수
컬럼이름 변경 : rename(columns) -> 딕셔너리 사용
CCTV_Seoul.rename(columns={'기관명':'구'},inplace=True) # inplace=True => 현재 분석한 결과를 저장하는 함수, 기본값은 False로 되어있음
CCTV_Seoul.head()
2. 엑셀파일 읽기 - 서울시 인구 현황
pop_Seoul = pd.read_excel('data/population_in_Seoul.xls')
pop_Seoul.head()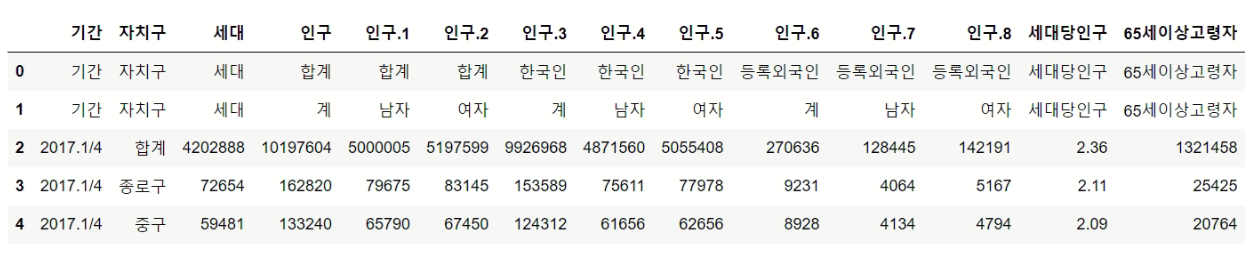
원하는 행, 열 데이터 읽기 : header, usecols
# header : 읽고 싶은 row index(0번 부터 시작) / header=2, 행데이터 가져오기 => 2번 로우 데이터부터 읽기
# usecols : 읽고 싶은 column 선택 / usecols='B,D,G,J,N', 컬럼데이터 가져오기 => 엑셀에 B,D,G,J,N 컬럼 데이터만 읽기
pop_Seoul = pd.read_excel('data/population_in_Seoul.xls', header=2, usecols='B,D,G,J,N')
pop_Seoul.head()
컬럼명 변경
pop_Seoul.columns = ['구','인구수','한국인수','외국인수','65세이상고령자수']
pop_Seoul.head()
.info() => 변수 정보 확인
CCTV_Seoul.info()
pop_Seoul.info()
3. 결측치 확인
pop_Seoul['인구수'].isnull() # 결과값 True/False로 반환
# boolean 인덱싱
# -> True 값만 인덱싱
pop_Seoul['구']
# 결측치인 값만 가져오기
pop_Seoul[ pop_Seoul['인구수'].isnull() ]
결측치 삭제
pop_Seoul.drop(26, inplace=True) # 삭제한 결과값 바로 할당하기 => inpalce=True or 변수에 할당하기
pop_Seoul
4. CCTV 수가 많은/적은 지역 파악하기 (각각 5개)
- 많은 지역 5개
# 값을 기준으로 정렬, 기본값 : 오름차순
# ascending= False -> 내림차순 정렬
CCTV_Seoul.sort_values(by='소계', ascending=False).head()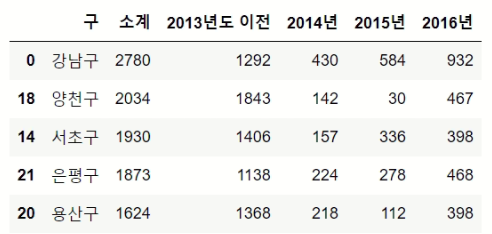
- 적은 지역 5개
CCTV_Seoul.sort_values(by='소계').head()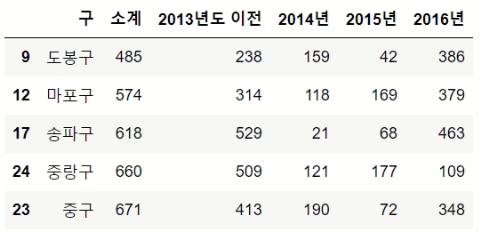
CCTV_Seoul.sort_values(by='소계', ascending=False).tail()
5. 데이터 병합
CCTV_구_set = set(CCTV_Seoul['구'].unique())
CCTV_구_set
pop_구_set = set(pop_Seoul['구'].unique())
pop_구_set
차집합 연산
pop_구_set - CCTV_구_set # pop에는 합계라는 데이터셋이 추가로 있다.
CCTV_구_set - pop_구_set
pop_Seoul.drop(0).head(3)
data_result=pd.merge(CCTV_Seoul,pop_Seoul, on="구")
data_result.head()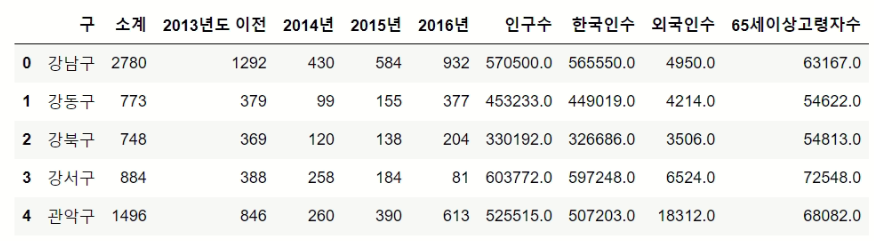
6. 인구수 대비 CCTV 비율이 높은/낮은 지역 알아보기
- 특성공학 : 컬럼끼리 연산을 통해 의미있는 컬럼을 만드는 직업
data_result['인구수대비 CCTV비율']=(data_result['소계']/data_result["인구수"])*100
data_result.head()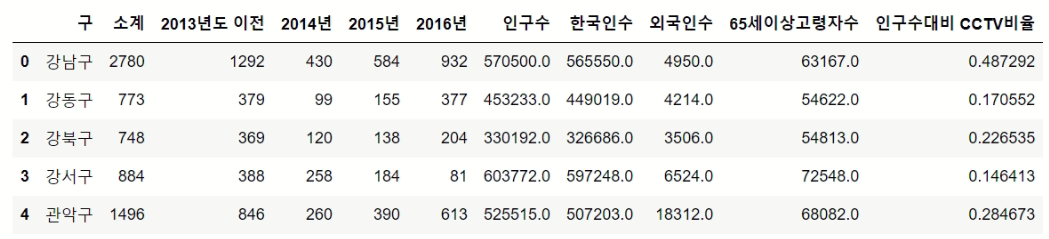
# 인구수 대비 CCTV가 적은 지역
data_result.sort_values(by="인구수대비 CCTV비율")
# 인구수 대비 CCTV가 많은 지역
data_result.sort_values(by="인구수대비 CCTV비율", ascending=False)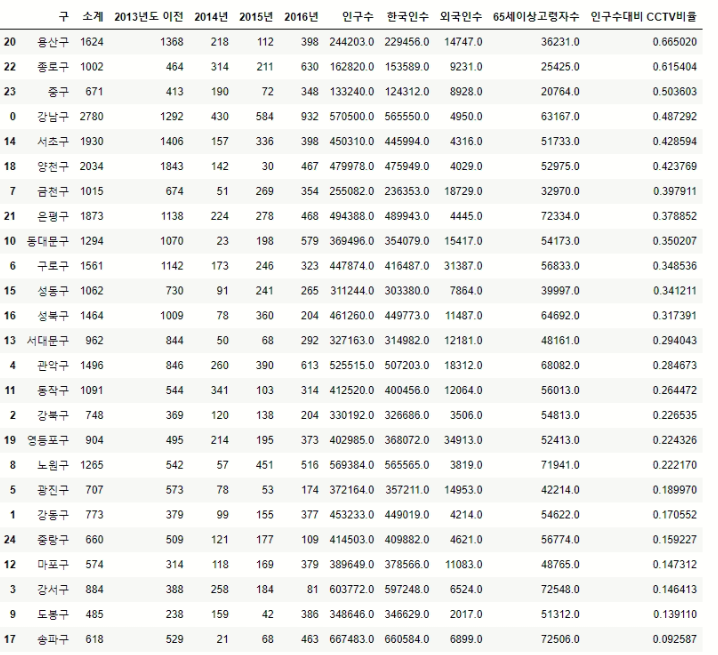
# 시각화
plt.figure(figsize=(10,7))
plt.grid()
plt.xlabel('인구대비 CCTV 비율')
plt.ylabel('구별')
plt.barh(gu,per)
plt.show()
gu=data_result.sort_values(by="인구수대비 CCTV비율")['구']
per=data_result["인구수대비 CCTV비율"].sort_values()7. 각 구별 CCTV 예측 값을 만들어보자
- 상관관계, 상관계수를 확인해서 CCTV 설치 숫자와 관련된 컬럼을 알아보자.
# 구 컬럼을 인덱스로 설정
data_result.set_index('구', inplace=True)
data_result.head()
data_result.corr()['소계']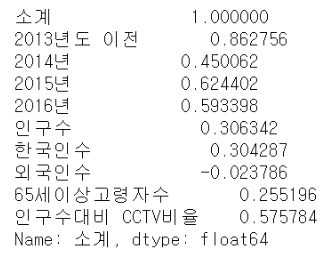
- 외국인수 -0에 가까운 약한 상관관계를 가짐.
- 13,14,15,16, 인구대비 CCTV 비율은 '소계' 컬럼을 계산 혹은 활용한 컬럼.
- ---> 부적합
- 인구수, 한국인수, 65세 이상 고령자수를 이용하자!
8. 머신러닝 모델을 이용해 학습을 해보자
from sklearn.linear_model import LinearRegression
model = LinearRegression() # 머신러닝 모델 생성
data_result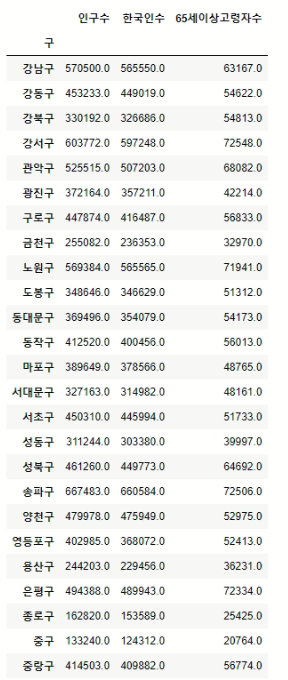
y=data_result['소계']
y # 학습용 정답
model.fit(X,y)
model.predict([[2000, 1000, 500]])
8-2. 각 구별로 CCTV 숫자를 예측하게 해보자.
CCTV_pre = model.predict(X)
CCTV_pre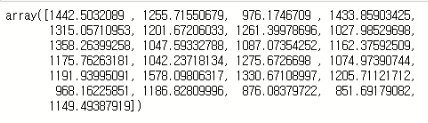
# 예측값과 실제값의 차이(오차) 구하기
error = np.abs(CCTV_pre - y) #절댓값
error
9. 결과 시각화
data_result['인구수'][0]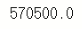
data_result['소계'][0]
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'],data_result['소계'], s=150, c=error)
for i in range(25):
plt.text(data_result['인구수'][i],
data_result['소계'][i],
data_result.index[i]) # 인구수, 소계 자리에 index(구)를 기입하겠다
plt.colorbar()
plt.xlabel('인구수')
plt.ylabel('CCTV 설치수')
plt.savefig('result.png')
plt.show()
'빅데이터 분석 서비스 > 머신러닝' 카테고리의 다른 글
| 머신러닝_네이버 영화 리뷰 감성 분석 (0) | 2021.09.12 |
|---|---|
| 머신러닝_보스턴 주택 값 예측(L1 Lasso, L2 Ridge) (0) | 2021.09.12 |
| 머신러닝_버섯 데이터 분류 실습(Decision Tree) (0) | 2021.09.04 |
| 머신러닝_iris 품종 분류 실습(K-Nearest Neighbors) (0) | 2021.09.04 |
| 머신러닝_BMI(체질량지수) 실습(K-Nearest Neighbors) (0) | 2021.08.29 |



