
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 서블릿
- 썸머스쿨예약
- 빅데이터
- K디지털크레딧
- iOS개발강의
- 전주독서실
- 코린이
- ux
- 리스트
- 바이트디그리
- jsp
- 패스트캠퍼스
- 전주스터디카페
- 파이썬
- Python
- 머신러닝
- 자바
- 광주직업학교
- 메시지시스템
- 자바페스티벌
- 코딩
- java
- 자바스크립트
- 딥러닝
- 스마트인재개발원
- 덴디컨설팅
- ui
- 스프링
- 내일배움카드
- 문제풀이
- Today
- Total
멀리 보는 연습
머신러닝_보스턴 주택 값 예측(L1 Lasso, L2 Ridge) 본문

4개월을 꽉 채웠다. 개강 초기에는 시간이 지나면 이 분야에 대해 자신감이 생길 줄 알았는데, 배울 수록 더 자신이 없어진다. 호호.. 앞으로 남은 2개월동안 더 열심히 해야겠다. 요즘은 머신러닝과 딥러닝을 거의 하루종일(?) 배우고 있는데, 물음표가 백만개는 떠다닌다. 뼛속부터 문과인 나에게 아주 큰 도전이다. 하루종일 뭔소린지 진짜 모르겠고요..? 아무튼 오늘 복습해볼 내용은 '보스턴 주택 값 예측' 이다. 두둥!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston # 보스턴 주택값 데이터일단 필요한 툴들을 가져오고,
data = load_boston()
보스턴 주택 값 데이터를 가져오기!
data.keys()dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
data['data']
data['target']
data['feature_names']array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')
- CRIM : 자치시별 1인당 범죄율
- ZN : 25000 평방 피트를 초과하는 거주 지역의 비율
- INDUS : 비소매 상업지역이 차지하고 있는 토지의 비율
- CHAS : 찰스강의 경계에 위치한 경우는 1, 아니면 0
- NOX : 10ppm 당 농축 일산화질소
- RM : 주택 1가구당 평균 방의 개수
- AGE : 1940년 이전에 건축된 소유주택의 비율
- DIS : 5개의 보스턴 직업센터까지의 접근성 지수
- RAD : 방사형 도로까지의 접근성 지수
- TAX : 10,000 달러 당 재산세율
- PTRATIO : 자치시(town)별 학생/교사 비율
- B : 1000(Bk-0.63)^2, 여기서 Bk는 자치시별 흑인의 비율
- LSTAT : 모집단의 하위계층의 비율(%), 주택 데이터 전체를 말함
- MEDV : 본인 소유의 주택 가격 중앙값(단위는 1,000달러) -> 답
df = pd.DataFrame(data['data'], columns= data['feature_names'])
df.head()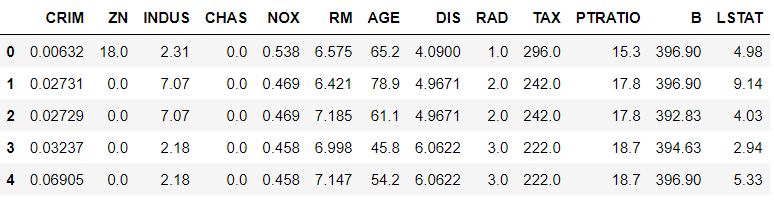
문제, 답
X = df
y = data['target']train, test로 분리 (7:3 비율)
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
LinearRegression
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_scoreL_model = LinearRegression()L_model.fit(X_train, y_train)LinearRegression()
L_model.score(X_test, y_test) # R square : 결정계수(0과 1 사이)
# 0으로 갈 수록 모델의 성능이 좋지 않다. 0.7 이상이면 괜찮다.
# 추정한 선형 모형이 주어진 자료에 적합한 정도를 재는 척도0.7224904405314632
result = cross_val_score(L_model, X_train, y_train, cv = 5)result.mean()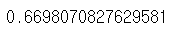
Linear Model 장점
- 결과예측 속도가 빠르다.
- 대용량 데이터에도 충분히 활용 가능하다.
- 특성이 많은 데이터 세트라면 훌륭한 성능을 낼 수 있다.
특성 확장
extended_X_train = X_train.copy()
len(X_train.columns)13
for i in X_train.columns:
for j in X_train.columns: #13의 제곱인 169번 반복
extended_X_train[i+'*'+j] = X_train[i]*X_train[j]extended_X_train.head() # 13개의 컬럼 + 169개의 컬럼 = 182개의 컬럼
L_model2 = LinearRegression()
L_model2.fit(extended_X_train, y_train)LinearRegression()
result2 = cross_val_score(L_model2,extended_X_train,y_train,cv=5)result.mean()0.6698070827629581
extended_X_test = X_test.copy()for i in X_test.columns:
for j in X_test.columns: #13의 제곱인 169번 반복
extended_X_test[i+'*'+j] = X_test[i]*X_test[j]L_model2.score(extended_X_test, y_test)
Linear Model 단점
- 특성이 적은 저차원 데이터에서는 다른 모델의 일반화 성능이 더 좋을 수 있다.
모델 정규화
- 가중치(w)값을 조정하여 제약을 주는 것
- L2 규제가 L1 규제에 비해 더 안정적이라 일반적으로는 L2규제가 더 많이 사용된다.
L1 규제 (L1 Regularization), Lasso(일부 특성이 중요할 때)
- 모든 원소에 똑같은 힘으로 규제를 적용하는 방법. 특정 계수들은 0이 됨. 특성 선택(Feature Selection)이 자동으로 이루어진다.
- 가중치의 제곱의 합이 아닌 가중치의 합을 더한 값에 규제 강도(Regularization Strength) λ를 곱하여 오차에 더한다.
- 어떤 가중치(w)는 실제로 0이 된다. 즉, 모델에서 완전히 제외되는 특성이 생기는 것이다.
- Lasso는 0에 수렴하는 컬럼들은 학습에서 제외한다.
L2 규제 (L2 Regularization), Ridge
- w의 모든 원소에 골고루 규제를 적용하여 0에 가깝게 만든다.
- 각 가중치 제곱의 합에 규제 강도(Regularization Strength) λ를 곱한다.
- λ를 크게 하면 가중치가 더 많이 감소되고(규제를 중요시함), λ를 작게 하면 가중치가 증가한다(규제를 중요시하지 않음).
- 특성의 값을 0으로 만들지 않고 0에 가깝게 만든다. 모든 컬럼들을 학습에 사용
Ridge
from sklearn.linear_model import RidgeR_model = Ridge()R_model.fit(extended_X_train, y_train)Ridge()
R_model.score(extended_X_test,y_test)0.8517747729978653
Ridge vs Lasso
from sklearn.linear_model import Lassoalpha_list = [0.001, 0.01, 0.1, 10, 100, 1000]
r_c_list=[]
l_c_list=[]
for i in alpha_list:
R_model = Ridge(alpha=i)
L_model = Lasso(alpha=i)
R_model.fit(extended_X_train,y_train)
L_model.fit(extended_X_train,y_train)
r_c_list.append(R_model.coef_)
l_c_list.append(L_model.coef_)R_df = pd.DataFrame(np.array(r_c_list).T, columns= alpha_list)
R_df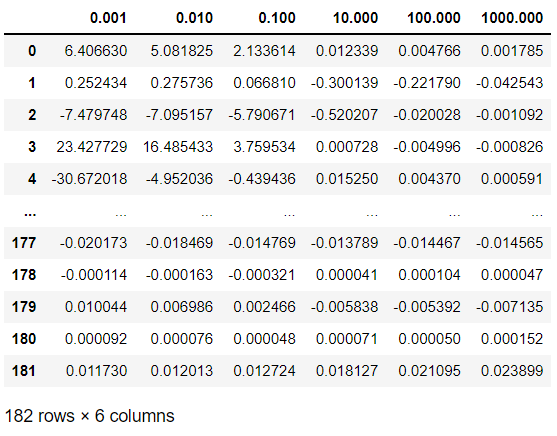
np.array(l_c_list)[0]
L_df = pd.DataFrame(np.array(l_c_list).T, columns= alpha_list)
L_df
'빅데이터 분석 서비스 > 머신러닝' 카테고리의 다른 글
| 머신러닝_네이버 영화 리뷰 감성 분석 (0) | 2021.09.12 |
|---|---|
| 머신러닝_버섯 데이터 분류 실습(Decision Tree) (0) | 2021.09.04 |
| 머신러닝_iris 품종 분류 실습(K-Nearest Neighbors) (0) | 2021.09.04 |
| 머신러닝_BMI(체질량지수) 실습(K-Nearest Neighbors) (0) | 2021.08.29 |
| 머신러닝_서울시 구별 CCTV 현황 분석 (1) | 2021.08.29 |



